
📚 New to this topic? Read our full guide: Generative AI Explained.
VibeThinker-3B: A Tiny Chinese AI Model That Beats Giants at Math and Coding
There is a small new AI model called VibeThinker-3B. AI means computer software that can read, write, and think a bit like a person. This little model is big news. It does as well as much larger models on hard math and coding tests.
The “3B” in its name means three billion parameters. Parameters are the tiny dials a model learns while it is trained. More parameters usually means a bigger and more costly model. So a 3B model is very small by today’s standards.
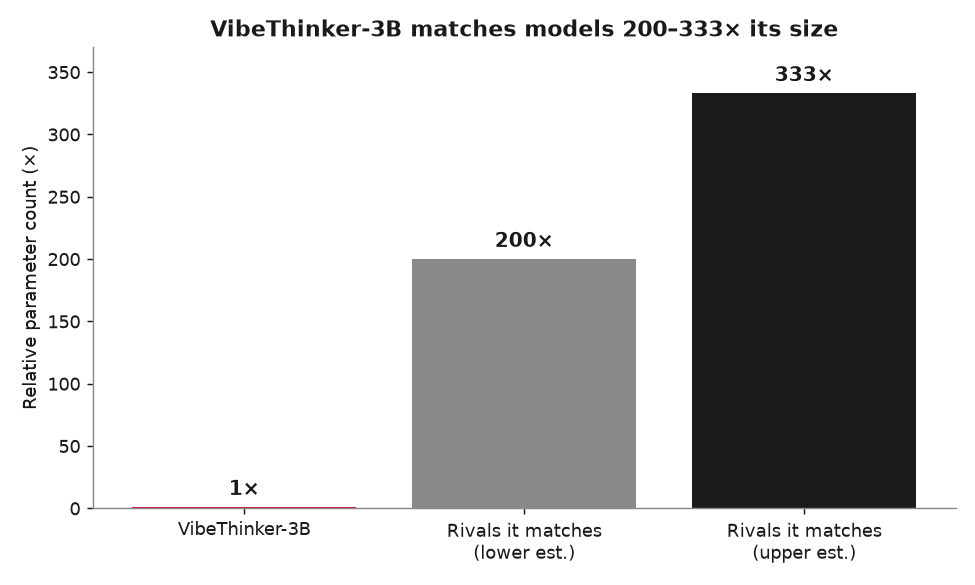
A technical report (a detailed write-up by the people who built it) was covered by The Decoder. It says VibeThinker-3B was made by Sina, the Chinese company that owns the social app Weibo. On some hard tests, it keeps up with models that are 200 to 333 times bigger. That is like a small car keeping pace with heavy trucks on a race track.
What VibeThinker-3B can do
The results tell two different stories. The first story is about tasks with a clear right or wrong answer. These include math contest problems and coding puzzles. On these, VibeThinker-3B matches top models like GLM-5 and Gemini 3 Pro.
On a coding test called LiveCodeBench, it beats every other model under 20 billion parameters. A benchmark is just a standard test. People use it to compare AI models in a fair way.
The second story is about facts, and here it does poorly. GPQA-Diamond is a test full of general knowledge questions. On this test, the model falls well behind the bigger ones. In short, it can think very sharply, but it does not “know” as many facts.
The LeetCode proof
The team wanted to be sure the model did not just memorize the test answers. When a model has secretly seen the answers before, that is called data contamination. To avoid this, they entered it into live LeetCode coding contests. LeetCode is a popular website where coders solve timed puzzles. These contests ran from late April to late May 2026, after training was already done.
VibeThinker-3B solved 123 of 128 problems on its first try. That put it ahead of GPT-5.2, Qwen3-Max, Kimi K2.5, and Claude Opus 4.6. Only three models did better: GPT-5.3-Codex, Gemini 3.1 Pro, and Gemini 3 Flash. And they were not far ahead. For a 3B model, this is amazing.
Benchmarks & specs
| Spec / test | VibeThinker-3B (as reported) |
|---|---|
| Maker | Sina (owner of Weibo), China |
| Size | 3 billion parameters |
| Base model | Built on Alibaba’s Qwen2.5-Coder-3B |
| Math (AIME26) | On par with DeepSeek V3.2 and Kimi K2.5 (200–333× larger) |
| Coding (LiveCodeBench) | Beats every model under 20B parameters |
| LeetCode contests | Solved 123 of 128 on first try; ahead of GPT-5.2, Claude Opus 4.6 |
| Knowledge (GPQA-Diamond) | Falls well behind much larger models |
| Availability | Open and free on Hugging Face and GitHub |
| Predecessor | VibeThinker-1.5B (launched November 2025) |
What it means: for tasks with clear, checkable answers, a tiny model can now rival the giants. But it still needs to be big to hold a lot of world knowledge.
The secret: better training, not more size
VibeThinker-3B is built on Alibaba’s Qwen2.5-Coder-3B. So the base is not new. Sina’s real work is the “post-training.” Post-training means everything done after the first, basic learning stage. The report says this extra work is what lifts a small 3B model close to the best.
Post-training happens in steps. First comes supervised fine-tuning. This means showing the model example questions with good answers, across math, coding, and chat. Then the team tunes it for hard problems that need many steps of thinking.
Next comes reinforcement learning. This is a way of training where the model gets a reward each time it gets something right. They did this one subject at a time, for math, coding, and science. Last, they joined all the skills into one model and polished it to follow instructions better. Their main point is simple. Good results come from smart training and clean data, not just more parameters.
A new theory about AI size
From these results, the authors share a new idea. They call it the “Parametric Compression-Coverage Hypothesis.” A hypothesis is just an idea you want to test. The idea is simple: different skills need different amounts of size.
Step-by-step thinking, like solving a math problem, uses a few patterns again and again. The model searches, checks, and joins results. These few patterns can be packed into a small model.
World knowledge works in a different way. To answer many open questions, a model needs a wide store of facts. That needs lots of parameters. So small models can think well but remember fewer facts. This gives small models a new role. They are not just cheap, cut-down copies. They are a real path to study on their own, next to the “bigger is better” path.
Part of a bigger pattern
Small models catching up to big ones on narrow tasks is now common. In April, Alibaba’s Qwen3.6-27B beat its older version on every coding test. That older version was 15 times larger. Falcon H1R 7B, from Abu Dhabi, matched models two to seven times its size, its makers said.
Older studies said small models hit a wall on multi-step thinking. But VibeThinker’s results on checkable tasks push back on that very idea.
Why it matters (especially for India and founders)
Small models are cheaper to run. They can even work on a single computer or phone. You do not need huge data-centre bills. For Indian founders and students, this lowers the cost of building AI products. You may not need the priciest giant model to make something truly useful for coding or math.
It also fits a clear money trend. Companies want cheaper AI that still works well. We saw this when Coinbase switched to cheaper Chinese models to halve its AI bill. One word of caution: VibeThinker is strong at thinking but weak at facts. So it is not a tool for every job. Match the model to the task. And as AI keeps getting better, expect more of your work to move to it. We cover that trend in our piece on the Anthropic survey on AI handling half of users’ work.
FAQ
What is VibeThinker-3B?
It is a small AI model with three billion parameters. It comes from Sina, the company that owns Weibo. It is built on Alibaba’s Qwen2.5-Coder-3B. It keeps up with much bigger models on math and coding tasks.
How can such a small model compete?
Sina says the secret is its post-training. That means its fine-tuning and reinforcement learning, not raw size. Its theory says thinking skills can fit into a small model, but broad facts cannot.
Where is its weak spot?
Facts. On the fact-heavy GPQA-Diamond benchmark, VibeThinker-3B falls well behind much larger models.
Is it available to use?
Yes. VibeThinker-3B is free and open for anyone on Hugging Face and GitHub.
The takeaway
VibeThinker-3B shows something clear. For thinking-heavy tasks like math and coding, smart training can beat sheer size. It will not replace big models for fact-rich work. But it proves small models are a serious path, not just a cheap option. For builders who want lower costs, that is exciting news. And it is one more sign that the AI race is not only about who has the biggest model.
Source: The Decoder (June 28, 2026), citing Sina’s technical report.


