
Moonshot AI’s Kimi K2.7 Code Pushes China’s Open Coding Models Forward
Moonshot AI has made a new coding model called Kimi K2.7 Code. A coding model is an AI program that can read and write computer code. This one helps people write software faster. It can also do big coding jobs that take many steps, all on its own. The company says it scores 21.8% higher than its older model, Kimi K2.6, on one of its main coding tests. The news comes as China keeps catching up with the top US labs on open coding models.
Moonshot AI shared the news on June 12, 2026. You can now get the model in three places: Hugging Face, the Kimi API, and the Kimi Code platform. (An API is a way for software to talk to the model over the internet.)
What Moonshot AI announced
Kimi K2.7 Code is what people call an “agentic” coding model. Agentic means it can plan and finish a long task step by step. It does not just answer one question and stop. Moonshot AI built it for “long-horizon” jobs. That just means big tasks that take many steps to finish.
The model is “open weights.” That means the company shares the real model files. So other people can download it and run it themselves. It uses a Modified MIT license. A license is the set of rules for using the model, and this one is fairly free and open. Teams can run it on their own computers with tools like vLLM, SGLang, or KTransformers.
How the model is built
Kimi K2.7 Code is a Mixture-of-Experts model. People often shorten this to MoE. In an MoE model, the AI has many small “expert” parts. But it only turns on a few of them for each piece of work. This saves time and computing power.
The model has 1 trillion total parameters. Parameters are the inner settings a model learns while it trains. More parameters usually means a bigger, stronger model. But only 32 billion of them turn on for each token. A token is a small chunk of text, like a word or part of a word. So the model is huge, yet it runs more cheaply than its size would suggest.
It has 384 experts in all. For each token, it picks 8 experts plus 1 shared expert. The model has 61 layers. It also uses a vision encoder called MoonViT, which adds 400 million parameters. A vision encoder lets the model read images and video, not just text. The model can hold 256K tokens of text at once. This is called its context window, which is how much text it can keep in mind at one time. 256K tokens is a lot, about as much as a small book.
The benchmark scores
A benchmark is a standard test used to check how good an AI model is. Moonshot AI shared several benchmark results. They compared Kimi K2.7 Code to the older K2.6. On its own Kimi Code Bench v2 test, the new model scored 62.0. The old one scored 50.9. That jump is the 21.8% gain the company talks about.
The new model did better on every other test too. On MCP Mark Verified, it scored 81.1 and beat Claude Opus 4.8, which scored 76.4. Moonshot AI says the new model uses about 30% fewer “reasoning tokens” than K2.6. Reasoning tokens are the hidden thinking steps a model takes before it answers. Fewer of them means lower cost and faster replies.
Benchmarks & specs
| Benchmark (as reported) | K2.7 Code | K2.6 | Change |
|---|---|---|---|
| Kimi Code Bench v2 | 62.0 | 50.9 | +21.8% |
| Program Bench | 53.6 | 48.3 | +11.0% |
| MLS Bench Lite | 35.1 | 26.7 | +31.5% |
| Kimi Claw 24/7 Bench | 46.9 | 42.9 | +9.3% |
| MCP Atlas | 76.0 | 69.4 | +9.5% |
| MCP Mark Verified | 81.1 | 72.8 | +11.4% |
| Spec | Detail (as reported) |
|---|---|
| Type | Mixture-of-Experts (MoE) coding model |
| Total parameters | 1 trillion |
| Active per token | 32 billion |
| Experts | 384 total; 8 + 1 shared per token |
| Layers | 61 (including 1 dense layer) |
| Vision encoder | MoonViT (+400M params); text, image, video |
| Context window | 256K tokens |
| Quantization | Native INT4 |
| License | Open weights, Modified MIT |
| API price | $0.95 / M cached input; $4.00 / M output tokens |
| Download size | ~595 GB (Hugging Face) |
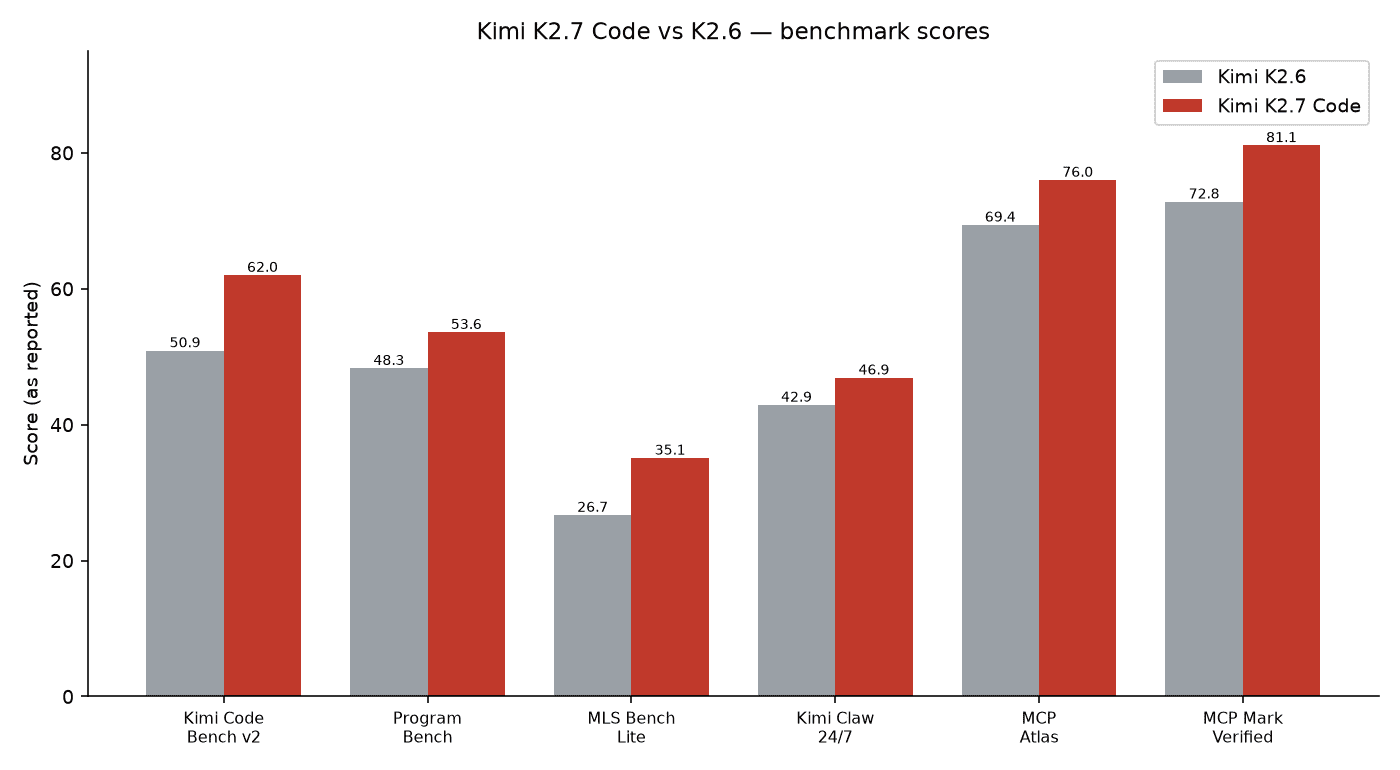
One thing to know: the model always runs in “thinking mode,” and you cannot turn this off. It also uses fixed sampling settings. (Sampling settings control how the model picks its next words.) These are temperature 1.0 and top_p 0.95. By default, it can give back up to 32,768 tokens in one answer.
How it stacks up against rivals
Moonshot AI did not say the new model beats everyone. It says GPT-5.5 still scores higher than K2.7 Code on most of the tests they ran. Against Claude Opus 4.8, the new model won on one test, MCP Mark Verified. So the result is mixed. But it shows an open model from China can fight closely with the strongest closed models from US labs.
FAQ
What is Kimi K2.7 Code?
It is a coding AI model from Moonshot AI. It is built to write software and to handle big, multi-step coding jobs on its own.
Is the model free to use?
The model files are open under a Modified MIT license. So you can download them and run them yourself for free. But using the official API costs money. It costs $0.95 per million cached input tokens and $4.00 per million output tokens.
How much better is it than Kimi K2.6?
On the Kimi Code Bench v2 test, it scored 62.0. K2.6 scored 50.9. That is a 21.8% gain. It also did better on every other test the company reported.
Can it beat GPT-5.5 or Claude?
Not on every test. Moonshot AI says GPT-5.5 leads on most tests. But K2.7 Code beat Claude Opus 4.8 on one test, MCP Mark Verified.
Why it matters (especially for India / founders)
For Indian founders and developers, open coding models are a big deal. Because the model files are open, teams can download the model and run it on their own computers. That can cut costs. It also keeps private code in-house, instead of sending it to an outside service.
Strong open models also give people more choice. Startups no longer have to rely on just one or two US providers. Cheaper, capable coding AI can help small teams build more software with fewer people. But there is a catch: the model needs powerful hardware to run at home. The download alone is about 595 GB. So most small teams will likely start with the API instead.
The bigger trend is clear. China’s open models keep getting better fast. They now match the best closed systems on some tasks. For builders everywhere, that usually means better tools at lower prices.
The main point: Kimi K2.7 Code is not the top model on every test. But it is a strong, open, and cheaper choice. It pushes China’s open coding models forward. For founders watching their money, more real competition in coding AI is good news.
Source: MarkTechPost


