
Meta Fundamental AI Research (FAIR) has released Brain2Qwerty v2, a significant update to its non-invasive brain-to-text decoding system.
While v1 (introduced in early 2025) focused primarily on decoding one character at a time as a user physically typed, v2 transitions the architecture into full-sentence decoding from raw brain waves—approaching the accuracy levels of surgically implanted brain-computer interfaces (BCIs) without opening the skull.
The primary objective is to build safe, non-invasive communication channels for patients suffering from severe brain lesions, locked-in syndrome, or advanced ALS.
1. The Core Performance Metrics
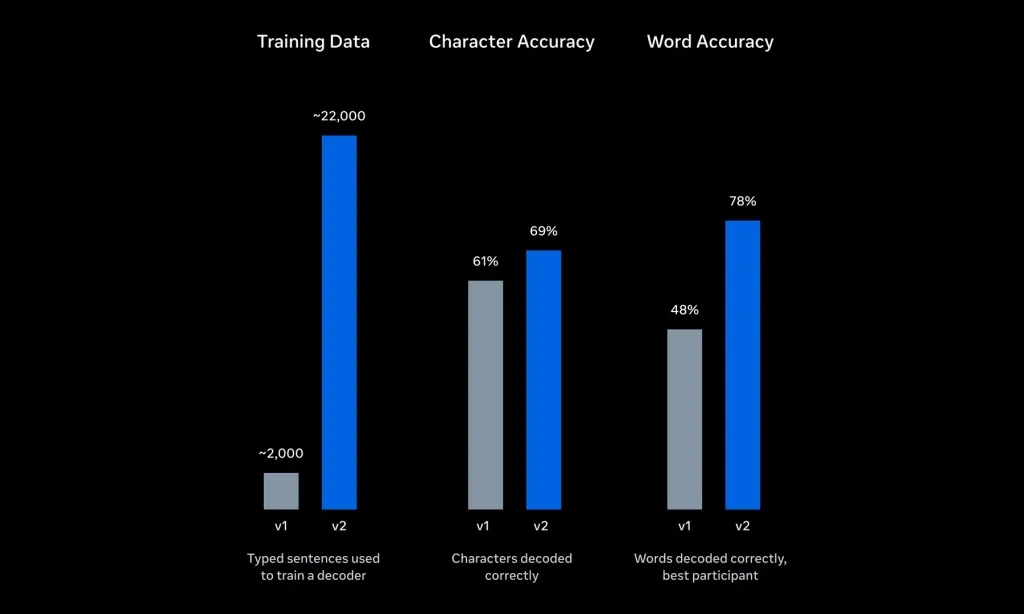
By leveraging a massive data collection effort (over 22,000 sentences gathered across 90 hours of magnetoencephalography (MEG) data), v2 drastically collapses the error margins traditionally associated with reading brain data through a scalp:
| Performance Metric | Brain2Qwerty v1 (2025) | Brain2Qwerty v2 (June 2026) |
| Average Word Error Rate (WER) | ~92% (8% accuracy baseline) | 39% WER (61% Word Accuracy) |
| Best Participant WER | ~81% | 22% WER (78% Word Accuracy) |
| Sentence-Level Clarity (Best Subject) | Highly fragmented character soup | 47% of sentences decoded within $\le 1$ word error; 28% completely perfect. |
2. Under the Hood: The Architectural Shift
The massive jump in performance comes from ditching handcrafted neural-event pipelines and replacing them with a highly contextual, end-to-end deep learning framework:
[ Raw Continuous MEG Stream ] ──► Conformer Encoder (Extracts Spatial/Temporal Brain Signals)
│
▼ (Connectionist Temporal Classification)
[ Asynchronous Tokenizer ] ──► Groups signals into word-like chunks at predicted space boundaries
│
▼ (LoRA Fine-Tuned Language Layer)
[ LLM Semantic Bridge (Qwen) ] ──► Applies context to smooth out noisy neural data into natural language
- Asynchronous CTC Decoding: Version 1 required strict “synchronous” logging—it needed to know the exact millisecond a user’s finger struck a physical key. Version 2 utilizes Connectionist Temporal Classification (CTC). Because it has 10x more data per subject, it can decode text continuously from a fluid stream of brain activity without needing keystroke-locked timing markers.
- The LLM “Spellchecker”: Meta integrated a 4-billion-parameter language model (fine-tuned using Low-Rank Adaptation, or LoRA, per subject) directly into the backend. If the neural signal is incredibly faint or noisy, the LLM reads the surrounding context of the sentence to infer what word the user most likely intended to type.
- “Auto Research” Optimization: In a fascinating engineering twist, Meta deployed autonomous AI coding agents to iteratively write, test, and refine the deep learning training configurations, automated code, and pipeline tweaks before engineers selected the final training state.
3. Real-World Failure Modes: Human-Like Errors
One of the most profound findings highlighted in Meta’s research paper is how the model fails. Because v2 utilizes a massive semantic language model layer, it has completely stopped spitting out unreadable gibberish.
When it makes a mistake, it fails in a distinctly human, grammatically coherent way:
Ground Truth (What the user thought): “The robot moved slowly yet it was very efficient.”
Brain2Qwerty v2 Output: “The robot moved slowly but it was very efficient.”
4. The Digital Brain Project and Open Source Commitments
Alongside the announcement, Meta confirmed it is fully open-sourcing the training code for both Brain2Qwerty v1 and v2 to accelerate global neuroscience benchmarks. Its primary research partner—the Basque Center on Cognition, Brain and Language (BCBL)—is simultaneously releasing the v1 dataset.
The release forms the core of Meta’s Digital Brain Project, backed by a $5 million fund to create open neuroscience data frameworks. This include its TribeV2 model for perception encoding, NeuralSet for massive-scale brain data ingestion, and NeuralBench to systematically score upcoming neural models against standardized tasks.
The Hardware Catch: While this is a massive victory for AI-driven neuroscience, a consumer product is still years away. The system requires a massive, stationary, and incredibly expensive Magnetoencephalography (MEG) helmet situated inside a magnetically shielded laboratory room. The near-term pipeline will focus on translating these algorithmic wins onto smaller, portable Optically Pumped Magnetometer (OPM) sensor arrays that can safely leave the lab.

