
In a massive shakeup for the enterprise AI market, Coinbase has transitioned its internal engineering infrastructure to run on Chinese open-weight AI models as the default setting.
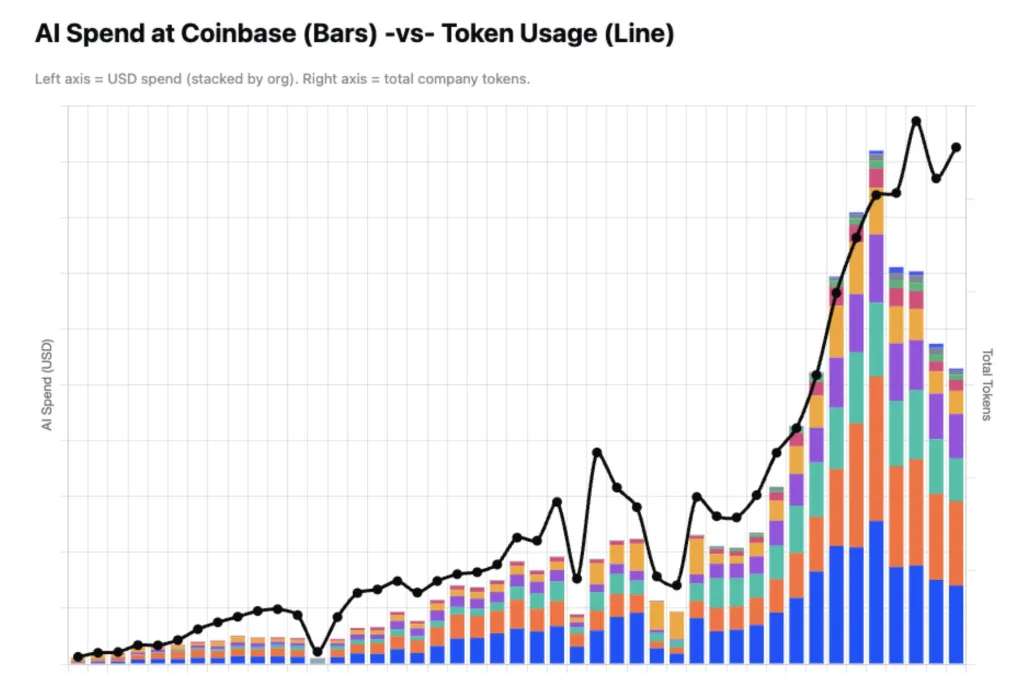
The disclosure, shared by Coinbase CEO Brian Armstrong, revealed that the crypto giant has successfully slashed its internal AI spending by nearly half while allowing its developer token usage to continue growing at an exponential rate. The move highlights a brewing “pricing stress test” hitting major Western AI labs like OpenAI and Anthropic as heavily subsidized, top-performing alternatives from China hit the open market.
1. The Models: GLM and Kimi Over Western Giants
Coinbase’s internal LLM gateway has shifted its engineering defaults away from hyper-expensive frontier systems, replacing them with two highly competitive Chinese models:
- GLM 5.2 (Zhipu AI): An open-weight model that has stunned the developer ecosystem by scoring 62.1 on the SWE-bench Pro coding benchmark, actively beating OpenAI’s GPT-5.5 (58.6). Structurally, Zhipu’s model costs roughly $1.40 per million input tokens, compared to top-tier Western counterparts like Anthropic’s Claude Opus 4.8, which charges up to $5 for the exact same volume.
- Kimi 2.7 (Moonshot AI): Acclaimed for its massive context-window handling and efficiency, this model has been deployed to shoulder Coinbase’s high-volume, execution-level coding tasks.
[ Western Closed Models ] ──► Claude Opus 4.8 ($5/M input tokens) ──► Exploding Enterprise Bills
│
▼ (Coinbase Infrastructure Shift)
[ Chinese Open-Weight ] ──► Zhipu GLM 5.2 ($1.40/M input tokens) ──► Cut Expenses by ~50%
2. The Three-Layer Infrastructure Overhaul
Armstrong emphasized that the objective wasn’t to impose hard spending caps or suppress developer creativity—especially since 91% of engineers never reached the bank’s old usage ceilings anyway. Instead, Coinbase re-engineered its gateway around three core efficiency principles:
1.Implement Intelligent Routing:Task-Matching Economy.
The internal gateway automatically processes prompts and evaluates task difficulty. Routine code execution is routed to GLM 5.2 or Kimi 2.7, reserving top-tier frontier models like GPT-5.6-Sol or Mythos strictly for complex architecture planning, as using them for basic tasks is “overkill.”
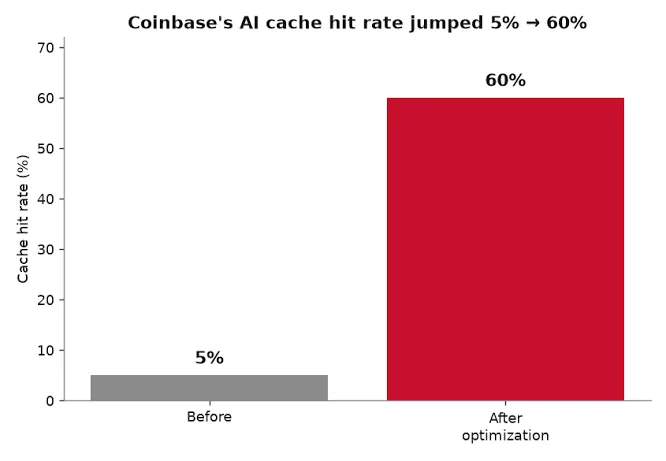
2.Deploy Aggressive Caching:From 5% to 60% Hit Rate.
Coinbase forced all internal queries to be strictly cache-aware. By optimizing its integration with tools like LibreChat, the platform skyrocketed its response-reuse cache hit rate from a measly 5% to a staggering 60%, drastically minimizing repeated inference costs.
3.Streamline Context Engineering:Eliminating Wasted Tokens.
Engineers are required to practice tight context hygiene. The platform mandates starting completely fresh chat sessions when switching tasks and narrowing file attachments to eliminate the system bloat of processing “wasted tokens.”
3. The Security Shield & Geopolitical Paradox
While the decision to route a major U.S. financial institution’s workflow through Chinese-designed architecture has drawn immediate geopolitical eyebrows, Coinbase bypassed the primary security trap through on-premise deployment.
Because GLM 5.2 uses a permissive open-weight MIT license, Coinbase doesn’t send a single byte of sensitive corporate code or data out to an API in Beijing. Instead, the company downloaded the model weights, modified the framework internally, and runs it directly on its own secure, private servers.
| The Corporate LLM Divide | Open-Source Strategy | Spending Accountability |
| The “Tokenmaxxing” Problem | Tech giants like Uber, Amazon, and Meta have recently reported massive internal budget overruns, with Uber burning through its entire 2026 AI coding budget by April. | Coinbase has tied token use directly to performance metrics. There are no hard caps, but a new rule states: “The more you spend on AI, the more impact we expect.” |
| Multi-Model Parallelism | Code reviews at Coinbase now utilize a parallel cross-validation layer. | Multiple cheap models check each other’s outputs concurrently to maintain quality without paying a premium to a single provider. |
By successfully decoupling token consumption from soaring costs, Coinbase’s blueprint is being closely watched by Silicon Valley. The pivot signals that as long as Western labs keep software costs locked behind expensive proprietary gates, enterprise clients will happily look across the globe to secure hyper-efficient, open-source alternatives.
