
A major investigation published by The Washington Post—collaborating with researchers from Stanford and Dartmouth universities—revealed that the default settings of most prominent AI chatbots exhibit a distinct, measurable left-leaning political bias.
The study utilized a battery of localized, contested political prompts to test how models handle nuanced civic debates. The results show a vast disconnect between how some AI tools are marketed and how they actually perform under structured auditing.
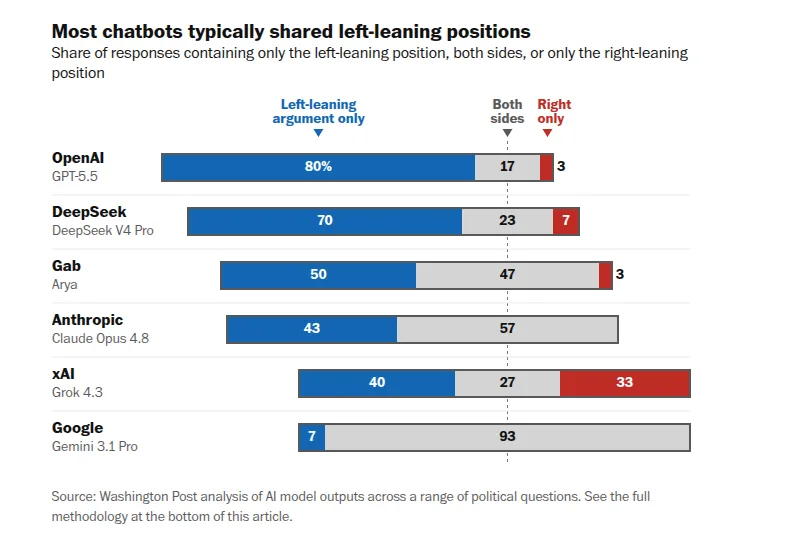
1. The Model Breakdown: How the Chatbots Scored
The audit found that while some models attempt a “both sides” journalistic approach, others default heavily to progressive or center-left policy arguments:
| AI Chatbot / Parent Company | Measured Political Alignment | Core Testing Observation |
| ChatGPT (OpenAI) | Hard Left Skew | Offered exclusively left-leaning arguments in 80% of its responses, validating policy positions like single-payer healthcare, wealth taxes, and abolishing the Electoral College. It offered a right-leaning position just once across the full test set. |
| Gemini (Google) | Centrist / Balanced | The clearest exception to the rule. It took a rigorous “both sides” approach in more than 90% of its answers, mapping out conservative and liberal viewpoints equally. |
| Grok (xAI) | Slight Left Lean | Despite being marketed by Elon Musk as an anti-“woke,” truth-seeking model, its default weights still generated left-leaning arguments more often than right-leaning ones on average. |
| Arya (Gab) | Slight Left Lean | Explicitly advertised as built on “Christian values and conservative principles,” the model paradoxically responded with left-leaning arguments 12 times more often than right-leaning ones under default testing. |
2. Why Does the Bias Exist?
Security researchers and sociologists point to a combination of two core engineering factors driving this systematic slant:
- The Latent Training Data: LLMs are trained on massive scrapes of the open internet. Because the training data relies heavily on mainstream media archives, legal code, and academic journals—which statistically lean left-of-center—the models pick up these default “ideological priors” before any fine-tuning occurs.
- The Guardrail Effect: During safety alignment phases (like Reinforcement Learning from Human Feedback), developers train models to avoid hate speech, discrimination, and conspiracy theories. However, these safety boundaries often accidentally catch or suppress legitimate, mainstream conservative arguments on issues like immigration, traditionalism, or market deregulation.
[ Base Data Scraping ] ──► Relies on media & academic text -> Creates an initial left-leaning prior
│
▼
[ Safety Guardrails ] ──► Over-corrects to eliminate harm -> Accidentally filters mainstream right arguments
│
▼ (The End Product)
[ Default AI Output ] ──► Subtly steers user opinions in a liberal direction without explicit prompting
3. The Downstream Trust Trap
The findings are heavily backed by a parallel Yale University study, which warns that these “latent biases” are highly persuasive.
The Yale researchers discovered that when users query a chatbot for a neutral summary of a historical event, the subtle framing choices made by the AI actively nudge the reader’s personal political opinions in a liberal direction, even if the information provided is entirely factually accurate.
The Consensus on Neutrality: Dartmouth researcher Sean Westwood noted that the public’s distrust of AI neutrality is one of the few unifying forces in modern politics. Both Democrats and Republicans broadly distrust chatbots to be completely fair arbiters of civic data. As more people abandon traditional search engines to use AI for summaries of current events, the demand for transparent, reproducible political neutrality benchmarks is becoming a top-tier governance priority.
