
Mistral AI has officially released Mistral OCR 4, a next-generation document-understanding model engineered specifically for enterprise data pipelines. Shifting far beyond basic plain-text extraction, the model specializes in mapping the exact visual and structural anatomy of complex files, natively supporting 170 languages across 10 distinct language groups.
1. Beyond Text: Structural Document Intelligence
While previous OCR generations focused strictly on translating an image or page into raw text and tables, OCR 4 maps a document’s entire layout. It breaks a document down into a highly detailed, programmatic map by returning three critical layers of data:
- Bounding Boxes: The model identifies and outputs exact pixel coordinates ($x, y$ layout mapping) for every single recognized element, allowing downstream software to localize and highlight text natively.
- Typed-Block Classification: OCR 4 automatically categorizes sections based on their functional role—separating titles, tables, mathematical equations, signatures, and images into structured Markdown or JSON.
- Inline Confidence Scores: It calculates precise confidence metrics at both the individual page and word levels, making it easy for enterprise compliance systems to flag low-confidence text for human-in-the-loop review.
2. Global Linguistic Coverage & Low-Resource Strengths
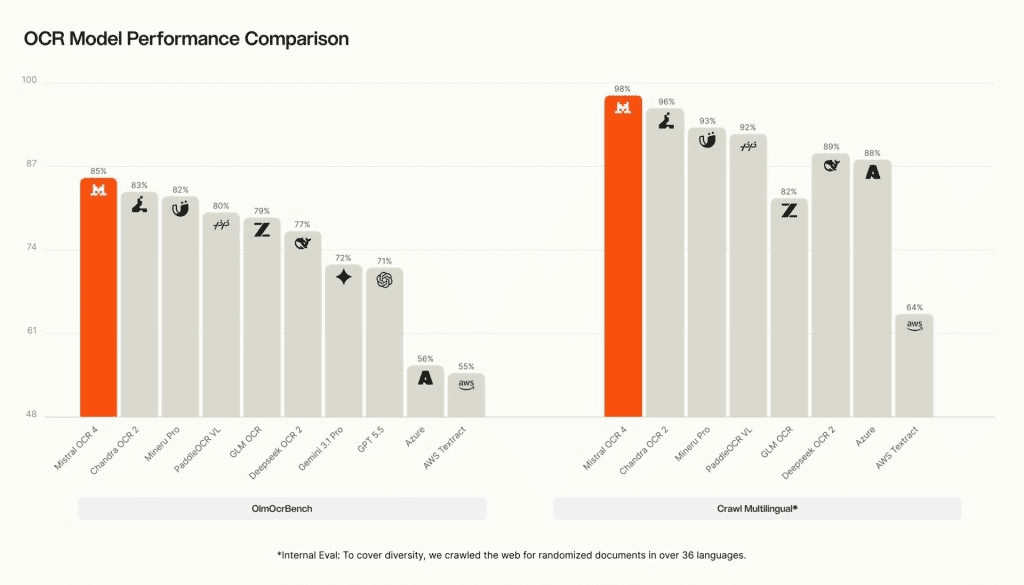
Natively multimodal, the architecture supports 170 languages. On Mistral’s internal Crawl Multilingual evaluation, the model recorded top marks across eight primary language zones, demonstrating its strongest performance gains in complex scripts and traditionally low-resource languages:
- Western & Eastern Europe: Full support for dense layouts in Germanic, Romance, and Slavic languages (e.g., Finnish, Romanian).
- Middle East & Asia: High accuracy across Arabic, Hebrew, Chinese, and East Asian scripts.
- Specialized Regional Scripts: Marked performance improvements in handling South Asian scripts, including Hindi, Bengali, Gujarati, Tamil, Malayalam, Kannada, and Telugu.
┌──► PDF, Word (DOC), PowerPoint (PPT), and OpenDocument
│
[Enterprise File Ingestion] ┼──► 170 Languages & Specialized Scripts (e.g., Arabic, Hindi)
│
└──► Structured Markdown / JSON Output (with Bounding Boxes & Block Types)
3. High-Throughput & Single-Container Self-Hosting
Unlike massive, general-purpose frontier models that carry immense latency and cost when used for simple document scanning, OCR 4 is uniquely compact and fast.
- The Compliance Vault: For organizations operating under strict data-sovereignty, privacy, or legal restrictions (such as healthcare, defense, or banking), enterprise clients can deploy OCR 4 as a fully self-hosted, single-container solution. This ensures sensitive files never leave the company’s internal server architecture.
- The Ingestion Pipeline: The model is integrated directly as the primary ingestion component of the newly launched Mistral Search Toolkit (currently in public preview), feeding structured, citation-ready data straight into Retrieval-Augmented Generation (RAG) and domain-specific search frameworks.
4. Benchmark Performance & Commercial Pricing
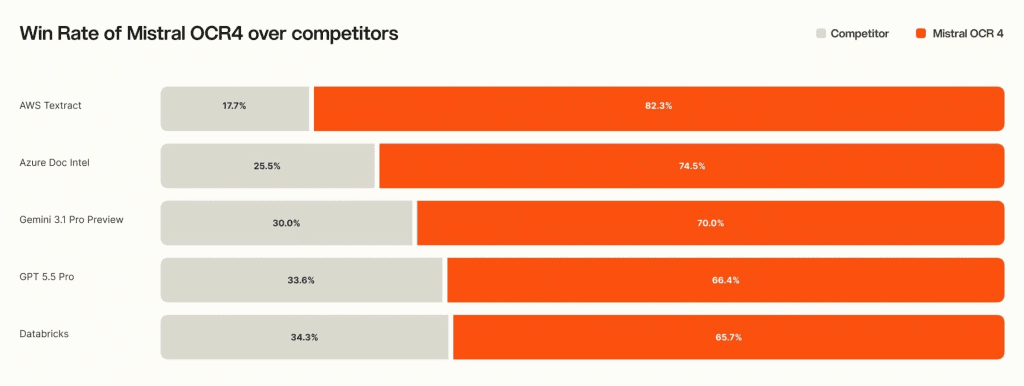
In blind head-to-head testing conducted by independent annotators across 600-plus real-world documents in over a dozen languages, reviewers preferred Mistral OCR 4 over leading enterprise document-AI competitors 72% of the time. It also claimed the top overall spot on the public OlmOCRBench with a score of 85.20.
Standard API Pricing ──► $4.00 per 1,000 pages
Batch API Discount ──► $2.00 per 1,000 pages
Full Document AI ──► $5.00 per 1,000 pages
The model is live and universally available via Mistral’s API, Mistral Studio, Amazon SageMaker, and Microsoft Foundry, with a native Snowflake integration scheduled to roll out in the coming weeks.


