
In a major push ahead of its upcoming developer showcases, Microsoft’s MAI Superintelligence Team has officially launched MAI-Image-2.5. This latest iteration of its in-house developed text-to-image series brings a massive step-change in text generation, spatial reasoning, and commercial asset design.
The announcement was accompanied by immediate validation from the blind-tested Artificial Analysis Image Arena (formerly LMArena) leaderboard, where MAI-Image-2.5 debuted at No. 3 globally, outranking several established generation suites in human evaluation.
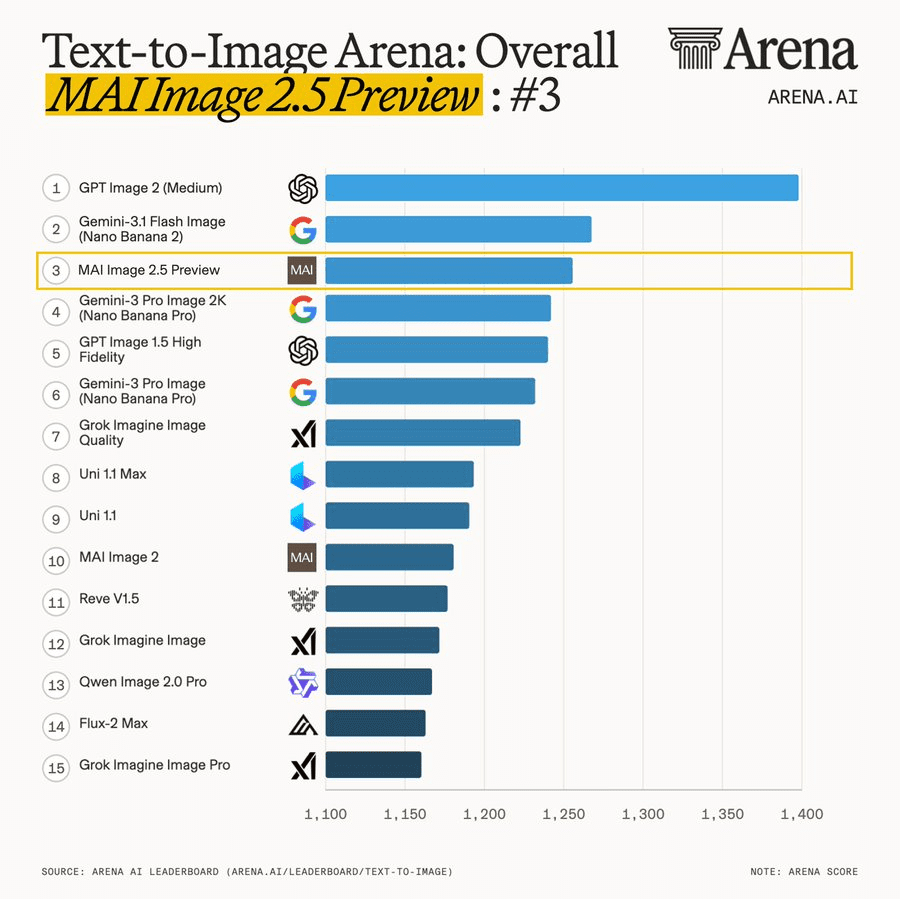
Accelerating the MAI In-House Timeline
Microsoft’s rapid release cadence showcases its intent to establish complete control over its media generation layer. The model’s evolution highlights how aggressively Microsoft is refining its proprietary visual architectures:
- October 2025: Launched MAI-Image-1, Microsoft’s first fully in-house developed text-to-image model, breaking into the Arena top 10.
- April 2026: Rolled out MAI-Image-2 and the high-speed MAI-Image-2-Efficient variants, boosting core photorealism.
- May 2026: Debuts MAI-Image-2.5 (Current Release), capturing the global top-3 ranking by prioritizing professional-grade instruction adherence.
Overcoming the AI “Text Rendering” Wall
Historically, text-to-image generators have struggled with rendering crisp typography, often resulting in gibberish letters, warped font faces, or completely scrambled phrasing. This limitation has long bottlenecked AI imagery from being deployed directly into production-ready graphic design pipelines.
MAI-Image-2.5 directly attacks this friction point. According to Mustafa Suleyman, CEO of Microsoft AI, the model delivers a complete overhaul in typographical fidelity:
- High-Contrast Text Precision: Words are sharper, maintaining crisp edges even when embedded inside dense, detailed product backgrounds or complex graphics.
- Structural Layout Coherence: The engine demonstrates advanced spatial and visual reasoning. It effectively balances lighting, scale, and multi-object layout constraints so that complex prompt elements hold together without clipping or distorting.
- Stylized Illustration & Cartoons: Alongside photorealism, the model’s training parameters have been optimized to handle stylized vector graphics, cartoon cell shading, and line art.
“Professional-grade creative work requires getting every detail right: the words on a poster, the label on packaging, the structure of a product shot, the way light falls across a scene,” the Microsoft AI team stated. “MAI-Image-2.5 makes meaningful gains in the areas that turn images from impressive to usable.”
Target Applications: Enterprise and Brand Assets
Given the model’s unique focus on spatial reasoning and sharp text generation, Microsoft is positioning the model heavily toward marketing teams, graphic designers, and corporate content developers. Key use cases targeted by the model include:
- Product Packaging Mockups: Generating precise labels, bottle geometries, and ingredient text maps for box-art prototyping.
- Branded Campaign Assets: Designing digital ad creative, banners, and event posters where structural text placement is vital.
- Training & Educational Graphics: Fabricating clear, properly labeled diagrams, educational worksheets, and slide vector graphics.
Deployment Timeline and API Specifications
While licensing, individual token cost structures, and final integration paths into mainstream productivity suites (like Copilot) have not yet been disclosed, Microsoft has outlined an immediate multi-tiered availability framework:
- The Arena Playground: Users can test the model blindly against competing architectures immediately on the active Arena text-to-image testing platform.
- MAI Playground & Microsoft Foundry: The model will officially deploy as a first-party creative engine within the web interface and developer Foundries over the next two weeks.
- The API Architecture: When it launches on Azure AI and Microsoft Foundry endpoints, developers can expect a native processing framework built on the MAI Image API structure (
/mai/v1/images/generations). This architecture utilizes high-context prompt limits (up to 32,000 tokens) and natively supports custom-aspect configurations maxing out at a standard 1,048,576 total pixels (equivalent to $1024 \times 1024$ resolution in standard PNG formats).


