

{kind=link}
In the rapidly evolving landscape of generative artificial intelligence, the industry focus is undergoing a monumental shift. The initial era of large language models was defined by single-turn conversational interfaces—chatbots designed to answer static prompts. Today, enterprise computing is demanding a vastly more complex paradigm: autonomous agentic orchestration.
AI agents do not operate in isolation; they execute long-running, multi-turn, iterative workflows. They must independently plan a sequence of actions, call localized software tools, evaluate system errors, read massive code repositories, and continuously adjust their execution paths over hours or days.
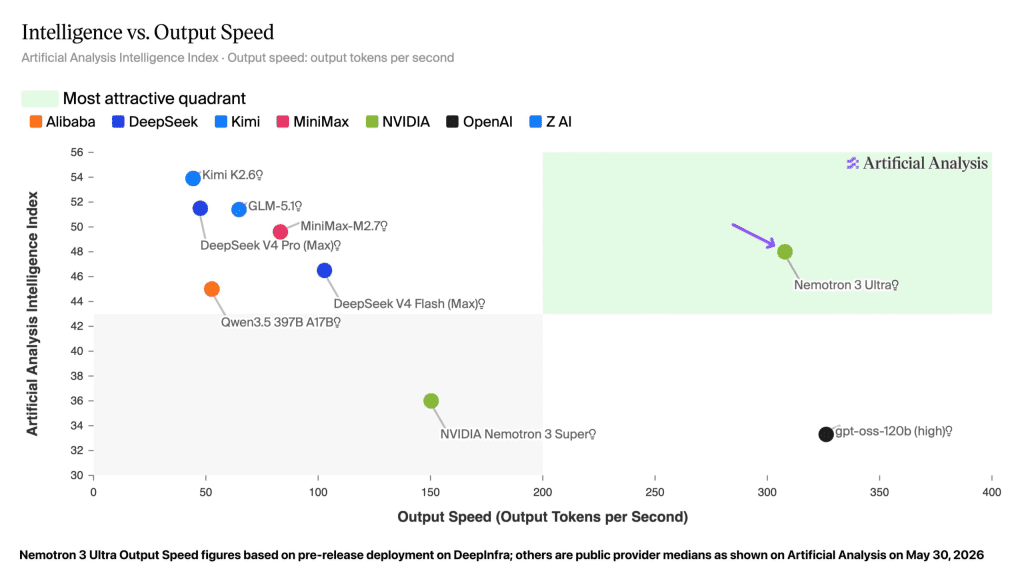
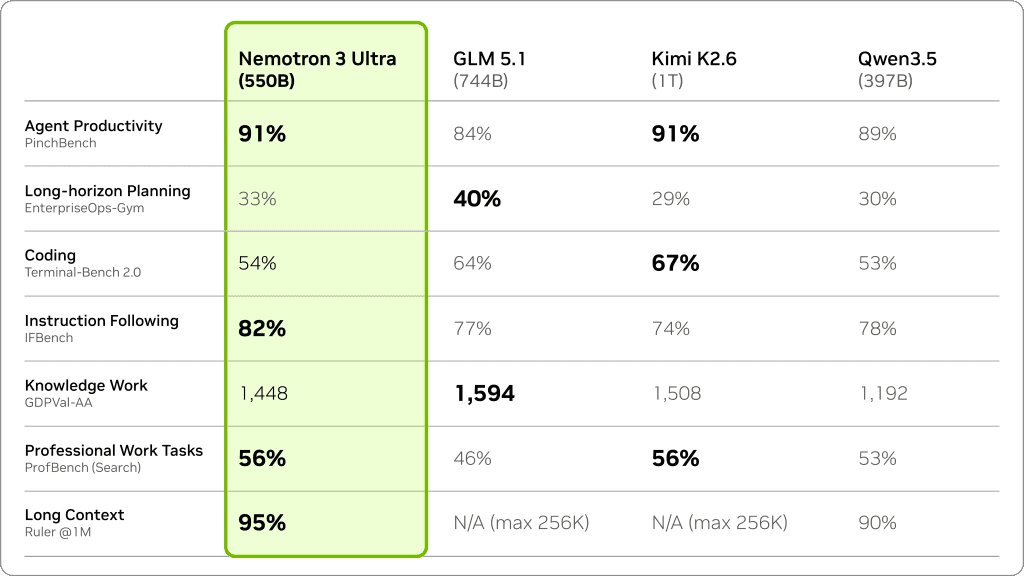
To provide the massive compute foundation required for these compute-intensive workloads, NVIDIA has officially released Nemotron 3 Ultra at the GTC Taipei conference. Scaling to a massive 550 billion total parameters, this open-weights model represents a radical departure from traditional dense Transformer architectures. By pioneering a hybrid structural framework, NVIDIA is directly addressing the core engineering bottlenecks—specifically memory retention decay and exponential compute costs—that have historically prevented autonomous agents from operating at true production scale.
1. Structural Engineering: Interleaving Mamba-2 with Attention
To understand the architectural significance of Nemotron 3 Ultra, one must first look at the inherent mathematical limitations of standard Transformer models when forced to handle long-context windows.
Traditional Transformers rely entirely on Self-Attention mechanisms. While exceptional at capturing complex relationships across text tokens, Self-Attention suffers from quadratic computational complexity ($O(N^2)$) in both time and memory relative to the sequence length. As an agent’s context window expands to accommodate dense codebases, multi-turn conversation logs, and real-time execution histories, the computational resources required to process each new token skyrocket, causing severe system latency and compounding operational costs.
NVIDIA engineers bypassed this computational bottleneck by designing a hybrid infrastructure that interleaves Structured State Space Models (SSMs), specifically utilizing Mamba-2 blocks, with highly selective Transformer Attention layers.
[Input Tokens] ──► [Interleaved Mamba-2 Layers (Linear O(N) Scaling)]
│
▼
[Selective Attention Layers (Quadratic Context Matching)] ──► [LatentMoE Expert Routing]
Mamba-2 layers operate with linear computational complexity ($O(N)$) relative to sequence length. They achieve this by processing data through a hardware-optimized, time-varying state space framework that acts like an incredibly efficient compressed memory stream. By using linear Mamba-2 blocks to handle the vast majority of sequential data processing and reserving quadratic Attention layers strictly for critical long-range context matching, Nemotron 3 Ultra effortlessly maintains an expansive 1-million-token native context window. The hybrid design ensures that an agent can retain an absolute, unbroken memory trace of complex, branching tasks without hitting the traditional thermal or latency barriers of dense systems.
2. Computational Efficiency: The LatentMoE Routing Engine
Processing a 550-billion-parameter network for every single token in a multi-turn agent workflow would be financially ruinous for most enterprise software budgets. To make the model commercially viable, NVIDIA integrated a sophisticated Latent Mixture-of-Experts (LatentMoE) infrastructure.
Instead of routing incoming tokens across a massive, fragmented array of standard physical experts—which regularly introduces severe communication overhead between GPU clusters—Nemotron 3 Ultra projects tokens into a tight, highly compressed latent dimension before performing expert routing.
- Sparse Activation Profile: Through this latent routing layer, the model selectively activates only 55 billion parameters per forward pass, meaning only 10% of the total network is active at any given moment.
- Token-to-Expert Specialization: The LatentMoE engine dynamically directs specific workloads to highly specialized internal pathways. Coding syntax, logical reasoning chains, and mathematical verification tasks are automatically routed to the precise subnetworks best equipped to handle them.
- Throughput Acceleration: Benchmarks logged on the Artificial Analysis Intelligence Index demonstrate that this sparse routing footprint allows Nemotron 3 Ultra to deliver up to 5x faster inference speeds over equivalent dense open frontier models during long-context tasks.
- Operational Cost Compression: Because the hybrid sparse framework processes complex workflows using fewer total active parameters per turn, it systematically compresses overall agent operational costs by 30%, throwing a financial lifeline to developers building continuous, autonomous enterprise systems.
3. Deployment Mechanics: NVFP4 Quantization and Open Integrations
Deploying an open model of this magnitude typically requires a massive, cost-prohibitive infrastructure footprint. NVIDIA has mitigated this barrier by releasing the model with a native NVFP4 (4-bit Floating Point) precision recipe.
Trained directly down to this ultra-low precision layer without the severe accuracy degradation that typically plagues post-training quantization, Nemotron 3 Ultra can be hosted locally with a fraction of the standard VRAM budget. The native NVFP4 format unlocks highly optimized speculative decoding and multi-token prediction (MTP) straight out of the box, maximizing hardware utilization on modern enterprise architectures.
NVIDIA has released the model weights under a permissive Open Model, Weights & Data License, actively making the pre-trained checkpoints, post-trained variations, and raw synthetic training data fully open to the global developer ecosystem. Day-0 integrations are fully live across critical open-source execution harnesses:
- vLLM & SGLang: Fully supported for high-throughput, hardware-optimized serving across enterprise A100, H100, and Blackwell GPU clusters.
- Cloud Endpoints: Accessible immediately via Amazon SageMaker JumpStart, OpenRouter, and as optimized NIM microservices via build.nvidia.com.
- Orchestration Frameworks: Tailored to integrate seamlessly with modern agentic execution environments, including Hermes Agent, OpenClaw, and Unsloth Studio.
By combining open-weights accessibility with a hybrid architecture that shatters the historical cost-curve of AI inference, NVIDIA is handing developers the precise tool needed to transition AI from a passive assistant into a highly capable, autonomous digital workforce.