

{kind=link}
Google DeepMind, in collaboration with the Gemma team, has officially launched DiffusionGemma (the “text diffusion” model built on the Gemma 4 family).
This is an experimental, open-weight model that abandons the traditional “typewriter-style” text generation used by almost all standard large language models. Instead of predicting words one by one from left to right, DiffusionGemma acts like an AI image generator—it starts with a canvas of random token noise and refines entire blocks of text simultaneously.
The downstream impact for developers, hardware architectures, and AI inference speeds is massive.
Shifting the Bottleneck: From Memory to Pure Compute
In traditional, autoregressive language models, the primary speed bottleneck is memory bandwidth. Every single token generated requires the system to reload the entire model’s weights from hardware memory.
DiffusionGemma bypasses this limitation entirely:
- 256-Token Parallelism: The model processes and denoises a 256-token canvas all at once in a single forward pass.
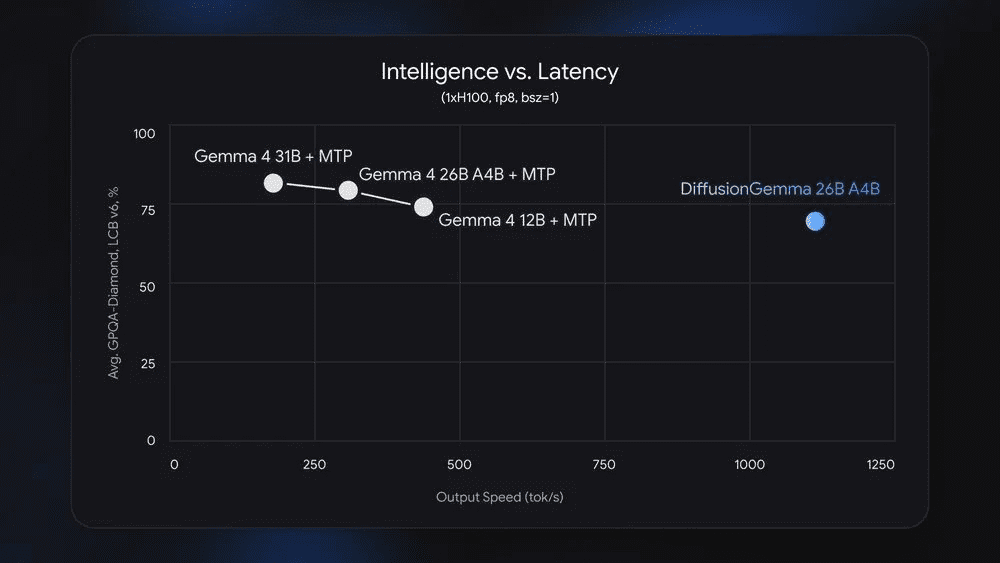
- 4x Faster Local Inference: Shifting the workload from memory bandwidth to compute plays directly to the strengths of modern GPUs. It clocks speeds of over 1,000 tokens per second on enterprise NVIDIA H100s and 700+ tokens per second on consumer-grade NVIDIA GeForce RTX 5090 cards.

Technical Architecture & Specifications
Google has structured the model to remain incredibly accessible for local deployments without demanding sprawling server racks.
| Feature | Specification |
| Base Architecture | Gemma 4 Family / Mixture-of-Experts (MoE) |
| Total Parameters | 26 Billion |
| Active Parameters | 3.8 Billion per forward pass |
| Hardware Footprint | Fits under 18GB VRAM limits when quantized (4-bit NVFP4) |
| License | Open-weights under permissive Apache 2.0 |
The Core Advantages of “Block-Based” Generation
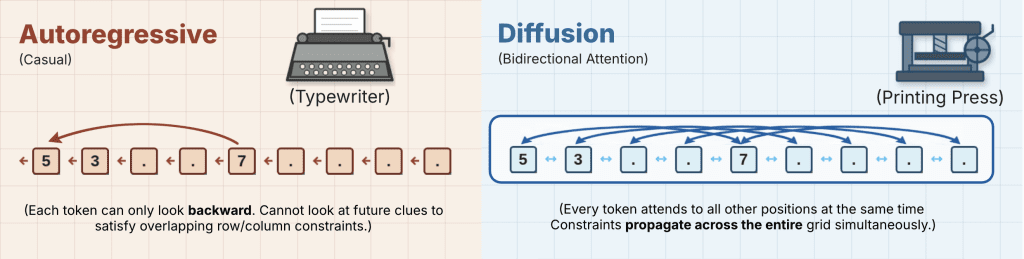
Because DiffusionGemma generates entire text blocks simultaneously, it uses bidirectional attention across the generation canvas. This creates unique capabilities that traditional text models struggle with:
1. Intelligent Self-Correction
As the model clears “noise” from the paragraph canvas over multiple steps, it reads the context of the whole block. If it notices a logical or grammatical error early in the block, it dynamically overwrites and self-corrects the text in real time before final output delivery.
2. Flawless Code & Markdown Structuring
Because all tokens attend to each other symmetrically during a pass, the model can perfectly close complex code brackets, complete nested formatting, or resolve non-linear data dependencies like mathematical graphs and code infilling without losing track of syntax.
3. Native Multimodal Input
The model utilizes an autoregressive encoder that natively accepts text, variable aspect-ratio images, and video inputs to serve as the prompt context, which the diffusion head then uses to stamp out the text answers.
The Catch: Quality vs. Speed Trade-offs
While DiffusionGemma is a monumental speed breakthrough for single-user local workflows, it is an experimental architecture with distinct trade-offs:
- Lower Absolute Quality: In broad reasoning tasks, its overall output accuracy still tracks slightly lower than standard, autoregressive Gemma 4 models.
- Low Concurrency Optimization: It is built explicitly to maximize local, single-accelerator performance. Under heavy, massive-scale cloud deployment workloads where thousands of user requests are batched together, traditional sequential text models still retain the throughput advantage.
Availability: The weights for DiffusionGemma are currently live and downloadable on Hugging Face, featuring day-zero serving and deployment integration support across vLLM, Unsloth, MLX, and NVIDIA NeMo.