

Alibaba Cloud has officially launched Qwen3.5-Omni, its most advanced “omnimodal” large language model to date. Released on March 29, 2026, the new series is designed to compete directly with global frontier models like GPT-5.3 and Gemini-3.1 Pro by natively processing text, images, audio, and video in a single, unified architecture.
The launch marks a significant leap from the previous Qwen3-Omni (released in late 2025), offering a “10x improvement” in processing speed and a massive expansion in multilingual support.
1. The “Omni” Advantage: Native Multimodality
Unlike models that “stitch together” separate tools for vision or voice, Qwen3.5-Omni is natively multimodal. It perceives and generates content across all formats simultaneously.
- Audio-Video Mastery: The model can process over 10 hours of continuous audio or 400 seconds of 720p video (at 1 FPS) in a single prompt.
- Real-Time Interaction: It supports streaming voice responses with latency as low as 230 milliseconds, enabling natural, human-like conversations.
- Semantic Interruption: In its real-time mode, Qwen3.5-Omni can distinguish between meaningful user interruptions and background noise, allowing for fluid “turn-taking” during a chat.
2. Model Sizes & Pricing
Alibaba has released the model in three distinct sizes to balance performance and cost, all available now via the Alibaba Cloud Bailian platform.
| Tier | Best For | Context Window | Pricing (per 1M tokens) |
| Plus | Complex reasoning & high-fidelity creative tasks. | 256k | ₹10 (approx. $0.12) |
| Flash | Speed-critical apps (Customer support, real-time). | 256k | ₹2 (approx. $0.02) |
| Light | Low-resource, high-volume mobile interactions. | 256k | ₹0.5 (approx. $0.006) |
Note: Pricing is approximately 90% lower than comparable tiers of Gemini-3.1 Pro, continuing Alibaba’s strategy of aggressive price leadership.
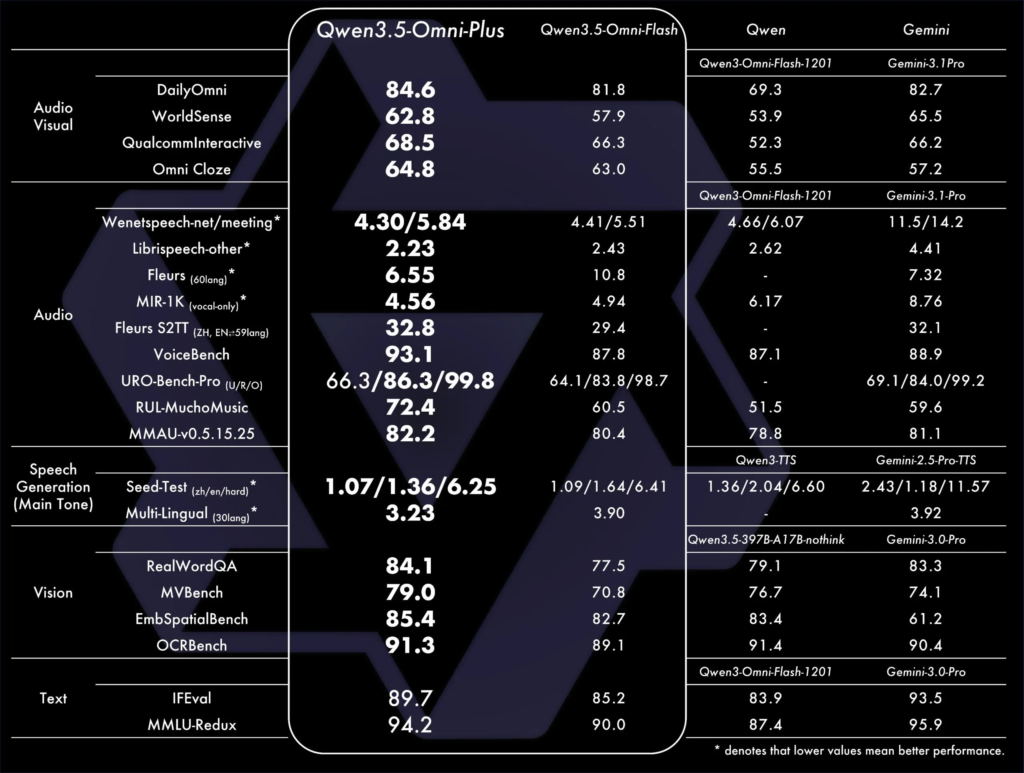
3. Key Capabilities & Benchmarks
In technical evaluations involving over 215 multimodal sub-tasks, Qwen3.5-Omni-Plus has achieved State-of-the-Art (SOTA) results:
- Multilingual Reach: Supports speech recognition in 113 languages and dialects and can generate speech in 36 languages, including highly accurate synthesis of 7 different Chinese dialects (like Minnan and Cantonese).
- Programming by Voice: A standout feature allows users to share a hand-drawn sketch via camera and explain their development ideas verbally; the model then generates the corresponding functional code in real-time.
- Voice Cloning: Users can now upload a short audio clip to create a custom AI assistant voice for personalized interactions.
4. Strategic Context: A Fast-Paced Rollout
Qwen3.5-Omni is Alibaba’s second major AI release in just six weeks, following the February launch of the text-heavy Qwen3.5 397B model.
By integrating web search and complex “Function Calling” natively into the Omni series, Alibaba is positioning Qwen as the primary “Operating System” for AI agents in Asia, serving over one million enterprise customers across the finance, automotive, and tech sectors.


{kind=link}